

現代社会において、不確実な事象を論理的に評価するスキルは必須です。
本講義では、機械学習の分野でも不可欠な「ベイズの定理」の本質について、予備校のノリで学ぶ「大学の数学・物理」のたくみ氏が解説します。
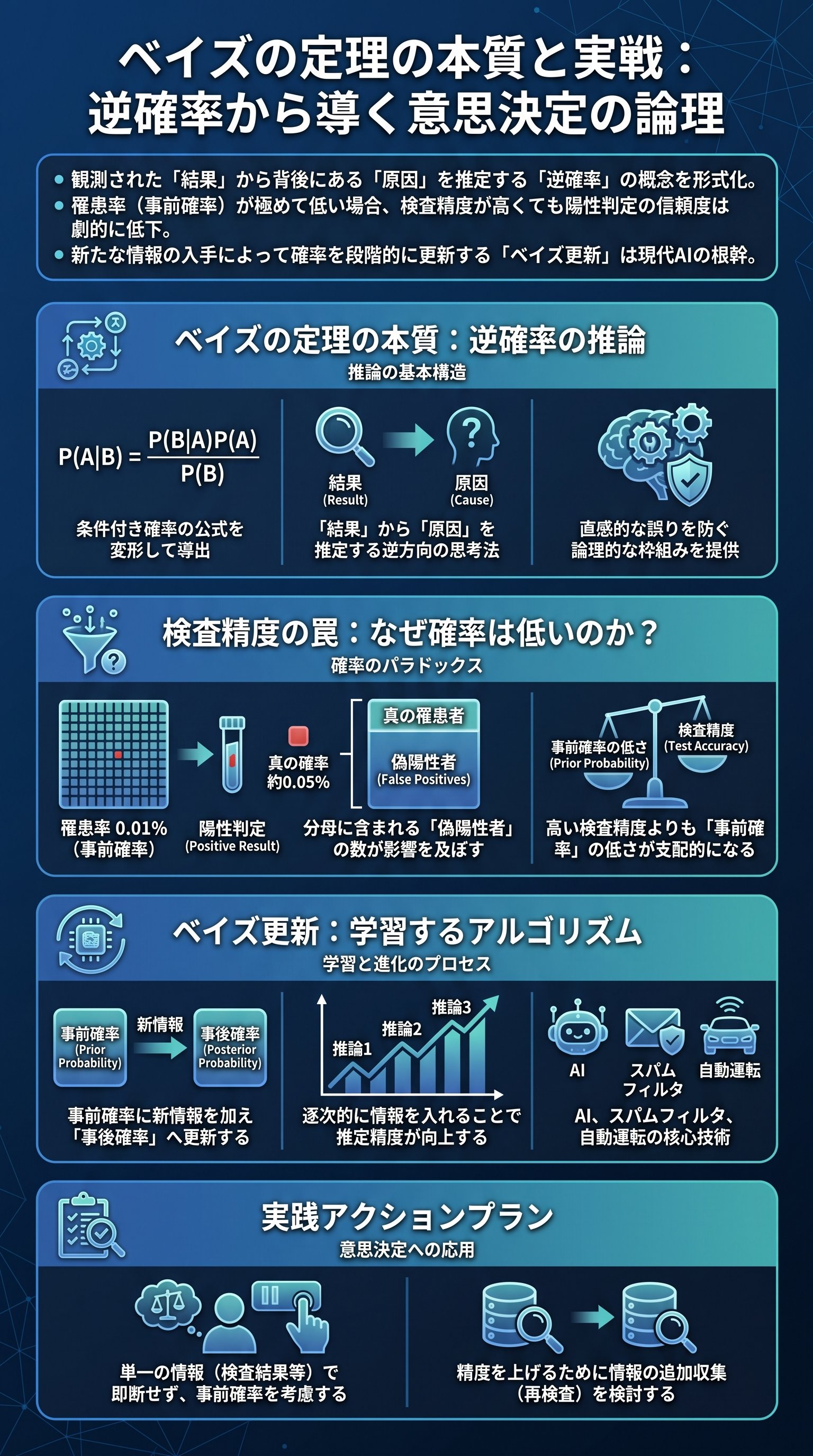
まず前提として理解すべきは、ベイズの定理が「条件付き確率」の変形そのものであるという点です。
条件付き確率 P(Y|X) とは、事象 X が起こった条件下で事象 Y が起こる割合を指します。
ベン図で視覚化すると、全体集合の中ではなく、集合 X という制限された領域内において Y が占める比率として定義されます。
この基本式を変形することで、P(X|Y) すなわち「Y という結果が得られた時に、その原因が X である確率」を導き出すことが可能になります。
これがベイズの定理の数理的構造です。
数学的には単純な変形に過ぎませんが、ここには「原因と結果の逆転」という深遠な意味が含まれています!
通常の確率は「ある原因(病気)があれば、この結果(陽性)が出る」という順方向の推論を行います。

しかし、ベイズの定理は「ある結果(陽性)が出た時、その原因(病気)は何であるか」という逆方向の推論を可能にします。
これを「逆確率」と呼び、実生活における多くの推論はこの形式をとります。
具体的な理解を深めるため、罹患率 0.01% という希少な病気の検査を例に挙げます。
検査の感度が 98%(罹患している人を正しく陽性と判定する確率)と非常に高くても、直感に反する結果が導き出されます。
なぜなら、病気でない人が誤って陽性と判定される「偽陽性」の存在が、分母となる全体の陽性判定数を押し上げるからです。
実際に計算を行うと、陽性と診断された人が本当に病気である確率は、わずか 0.05% 程度に留まります。
98% という検査精度が、事前確率(罹患率 0.01%)の低さによって打ち消されてしまうのです。
この事実は、単発の検査結果だけで一喜一憂することの危うさを数学的に証明しています!
したがって、医療現場などでは「再検査」が極めて重要視されます。

一度目の陽性判定という「情報」を得たことで、その人が病気である確率は 0.01% から 0.05% へと更新されました。
この更新された確率を「事後確率」と呼び、これを新たな「事前確率」として二度目の検査(情報収集)を行うことで、精度は劇的に向上します。
この「情報の入手によって確率を更新していくプロセス」こそがベイズ推定の神髄です。
データが蓄積されるたびに推論の精度が洗練されていく仕組みは、スパムメールのフィルタリングや自動運転技術など、現代の AI 技術の基盤として広く応用されています。
「原因」が不明な事象に対して、限られた「結果」から論理的にアプローチするための武器がベイズの定理です。
主観的な見積もりから出発しても、情報のアップデートによって客観的な真実に近づけるという性質は、ビジネスの意思決定においても強力な指針となります。
統計学の教科書として定評のある「プログラミングのための確率統計」などの文献でも、この概念は重要視されています。
数式の背後にある「情報による確率の更新」というパラダイムシフトを理解することが、データサイエンスを学ぶ上での第一歩となります。
複雑な事象を前にした時、直感に頼らずベイズの視点で確率を捉え直す姿勢が、現代人に求められるリテラシーと言えるでしょう。