The Context Bottleneck and Deepseek V4's Selective Memory Strategy

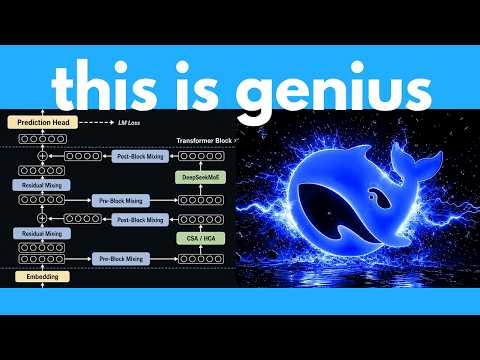
Deepseek V4 represents a paradigm shift in how large language models handle vast amounts of data. While traditional models struggle with the computational burden of a 1 million token context window, the Deepseek team has pioneered a solution that prioritizes efficiency without sacrificing intelligence. The primary challenge of long-context processing is the quadratic growth of comparisons: as the number of words increases, the hardware requirements for maintaining attention across those words explode. To address this, Deepseek V4 introduces a hybrid attention architecture that moves away from the 'remember everything equally' approach, instead adopting a more human-like selective focus.
The system utilizes Compressed Sparse Attention (CSA) to group tokens into small, dense summaries. By merging four tokens into a single representation, the model immediately reduces the sequence length by a factor of four, significantly lowering the memory footprint. However, compression alone is not the answer. To maintain high-speed performance, the architecture incorporates a Lightning Indexer for sparse selection. This mechanism acts as a rapid internal search engine, scoring compressed blocks and selecting only the most relevant subsets for the current task. This means the model does not scan the entire history for every word, but rather targets the specific information required to maintain the flow of conversation.
- CSA (Compressed Sparse Attention): Compresses tokens into groups of four to reduce sequence length.
- Sparsity: Employs an internal indexer to selectively retrieve only the most useful data blocks.
- Efficiency: Drastically reduces the Flops (floating-point operations) required compared to traditional attention mechanisms.
Heavily Compressed Attention and the Layered Precision Model

Beyond the initial sparse selection, Deepseek V4 employs Heavily Compressed Attention (HCA) to provide a broad, high-level understanding of the entire input history. In this mode, the model aggressively compresses up to 128 tokens—equivalent to an entire paragraph—into a single mathematical representation. This creates a highly summarized view of the distant past, allowing the model to afford a 'global' look at the information because the total number of blocks is greatly reduced. This layered approach balances the need for specific details with the requirement for general context, ensuring that the model remains grounded in the overall document structure.
To ensure that specific details are never lost in this sea of compression, the engineering team integrated a sliding window attention pathway. This component tracks the most recent 128 words with 100% fidelity, ensuring that the immediate context of a prompt is preserved exactly as it was written. By interleaving these three distinct strategies—heavily compressed summaries, selectively retrieved chunks, and uncompressed immediate windows—the architecture captures the best of all worlds. It maintains a sharp focus on the present while retaining the ability to reach back into a million tokens of memory for specific facts.
ここからが大事な
ポイントです
具体例・注意点・明日から使えるヒントを整理しています。
✨無料閲覧で全文 + 図解の完全版を3日間いつでも読み返せる
あなたの好きな動画も、
1分でAI要約
📚 お気に入り保存 + ✨ あなたの動画をAI要約
(無料登録10秒)
✏️ この記事で学べること
- ▸Mechanisms for handling 1 million tokens efficiently
- ▸Stability through manifold-constrained hyperconnections
10秒で完了・パスワード作成不要